本文整理自 2024 年 6 月 DataFunSummit 2024 OLAP 架构峰会 Lakehouse 湖仓一体化架构论坛的同名主题分享。
今天分享的主题是基于 Native 技术加速 Spark 计算引擎,大家将会了解到如何基于 ClickHouse 来改造 Spark 引擎,最终获得较为可观的性能提升。分享主要分为如下四个部分:1)Spark 性能优化背景;2)ClickHouse 性能优势解析;3)Spark Native 加速方案设计和实现;4)加速效果分
1 Spark 性能优化背景
1.1 Spark 简介
首先我们先简单介绍一下 Spark。
Spark 最初是诞生于 UC Berkeley AMPLab 的的一个实验项目,早期是用分布式的思路来处理机器学习过程中大量的迭代计算任务。在 2013 年贡献给了Apache 社区。后来逐渐发展为离线大数据处理领域最受欢迎的开源产品之一,另外在数据科学、机器学习、流式处理方面也有长足的发展。截止目前,Spark 开源项目有超过 2000 名的贡献者,38.6k 的 Star 数,在开源大数据领域的热度稳居第一梯队。

1.2 Spark SQL 概览
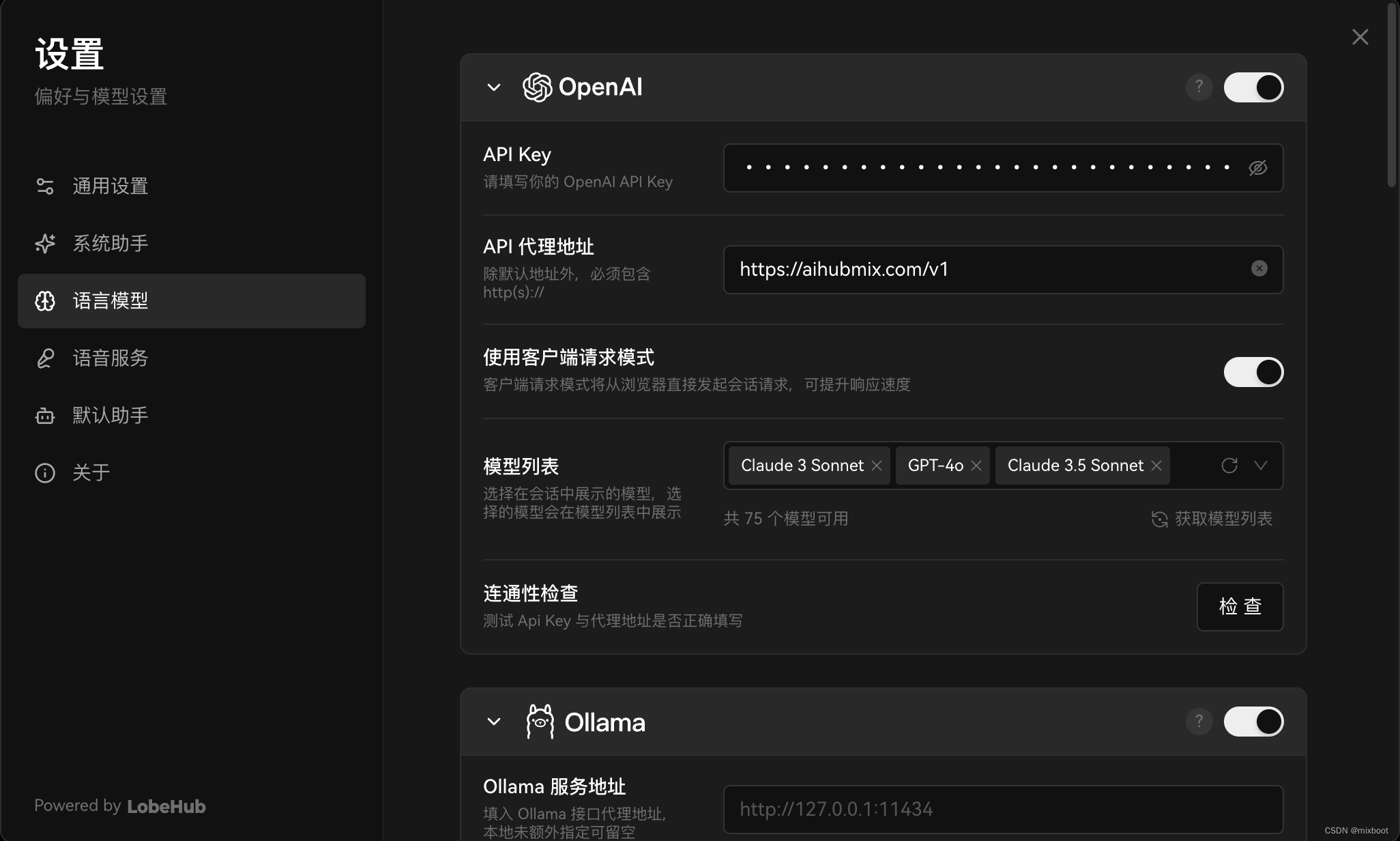
这里我们简单分析一下 SQL 的执行逻辑,进一步考虑一下可能存在的性能优化点。这里我们举个例子,比方说百度的某一个 PM 想查一下全国各个城市在 4 月 1 号那天的搜索量有多少。
这个需求写成一个 SQL 其实就是根据城市进行分组聚合。在 Spark 中执行该 SQL 的话,先要在 Driver 中进行一系列的处理:首先生成逻辑计划,进行多轮优化,最后生成物理执行。下一步 Driver 中会将物理计划切分成不同的 Stage,每个 Stage 依据数据分片的切分逻辑划分成大量的 Task,最终以 Task 为单位下发到 Executor 上完成对应数据分片的处理。
对当前例子而言,会生成两个 Stage,我们分别称其为 ShuffleMap Stage 和 Result Stage,每个 Stage 中可能包括了成千上万个 Task。而 ShuffleMap Stage 中的所有 Task 的执行逻辑其实是一样的,只是处理的数据分片不一样, Result Stage 中也是同样的情况。并且其执行逻辑都是由一些确定的 SQL 算子组成的,每个 SQL 算子的工作逻辑也是固定的,比如 Scan 算子可以读取任何 Spark 支持的数据格式,并生成 Spark 内部的数据格式交给下一个算子来处理。
从性能优化的角度,我们可以得出上述的 Spark SQL 执行过程如下两个特点:
-
Driver 中完成了非常复杂的处理逻辑,但是资源、时间消耗非常少,只占用一个线程,毫秒级的耗时;
-
Task 会占用大量的计算资源,通常也是任务执行耗时的主要组成部分,但是其执行逻辑都是由具体的 SQL 算子构成的。
1.3 Spark Task 概览
上节讲到了计算资源主要被 Spark Task 消耗了。这里我们从性能的角度对 Spark Task 做进一步的分析,并将其总结为两点:
-
Task 运行在 JVM 中;
-
Task 中的数据计算框架实际上是基于行式的。
从性能优化的角度看,Task 运行在 JVM 中是较难实现高性能的解决方案的。首先在 Java 中不方便调用 SIMD 等底层 CPU 指令;其次 JVM 基于 Heap 的内存管理机制实现了较好的安全性检查,但是对内存访问的效率偏低;最后,Java 中也较难生成高效的机器码。这里我们可以看个简单的例子,就是对一百万个整数求和,完整的示例代码[1]可以在 GitHub 上找到。
我们可以发现 Java 版本的耗时是 C++ 版本的 11 倍,主要的原因是 C++ 编译器自动实现了循环展开并且调用了 SIMD 指令,充分利用了 CPU 流水线特性,几乎实现了 CPU 性能最大化。
再看一下行式数据计算框架,下图右侧展示的就是 Spark UnsafeRow 的数据组织形式,每一行数据会申请一块内存,其中第一部分按位记录每个字段的 Nullable 属性,接下来每个字段占用 8 个字节的定长空间,最后部分记录超过 8 字节字段的数据。这样按行组织的数据首先对 JVM 的 GC 有一定的压力;其次其处理过程也是按行来进行计算的,这样是不方便编译器生成高效的汇编代码的。

1.4 Spark Task 性能优化构思
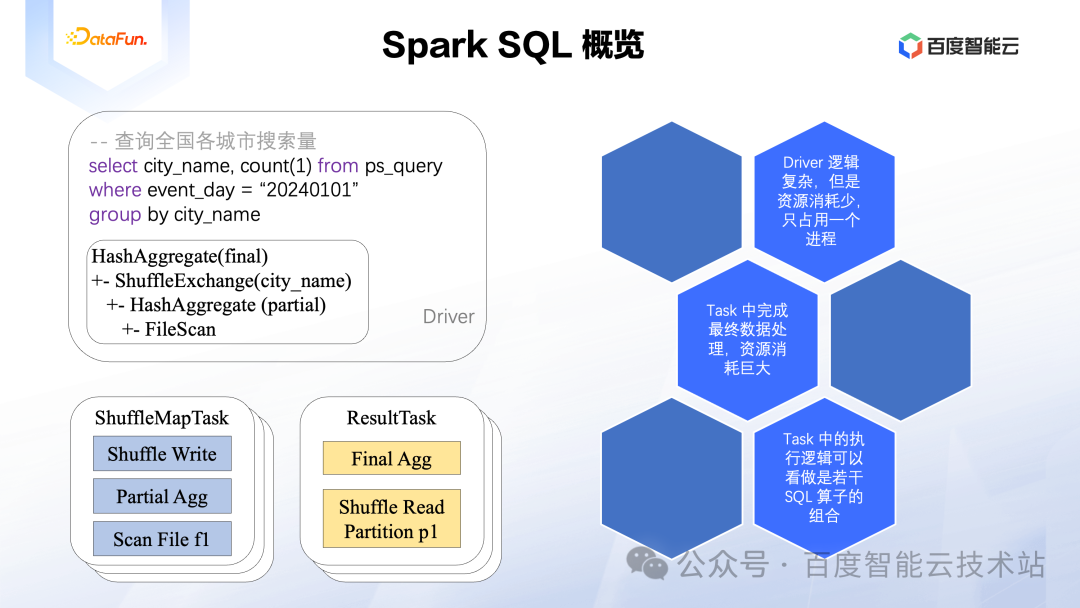
基于上述对 Spark Task 的性能分析,我们的优化思路其实也是比较直观的,也就是将 Spark 目前按行进行计算的模式改造为按列进行计算,并且使用 C++ 语言来重写该逻辑。
如图所示,以前面 SQL 的 Map Stage 为例,Task 中的执行逻辑总结起来就是三个算子。Scan 算子从文件中读取数据并解析为 Spark 的行式内存格式,Agg 算子完成数据的分组聚合逻辑,Shuffle 算子完成数据的切分逻辑。 目前Spark 虽然使用 Java 语言实现了上述逻辑,但实际上也可以用 C++ 语言重写上述逻辑。只不过 C++ 版本的实现中,Scan 出来的数据就不应该是行式的组织格式,而是列式的组织格式,接下来的 Agg 和 Shuffle 算子也都全部用 C++ 实现,并且消费列式数据格式。当然重写一个 SQL 内核引擎的工作量是巨大的。
实际上 Databricks 已经实现了类似上述逻辑的 C++ 版本 SQL 引擎内核,不过该实现是闭源的。从技术上讲,也可以不用完全重写这样的 SQL 引擎内核,而是选择一个性能足够强大的开源引擎,将其改造为符合上述要求的 SQL 引擎内核,那么可以只消耗较少的人力就能实现性能提升的目的。
1.5 ClickHouse as Spark SQL Backe
基于前面的分析,我们很容易想到可以将 ClickHouse 改造为一个 Spark 的 SQL 引擎内核,完成 Task 中的数据处理逻辑。
该设想能够实现的前提是,ClickHouse 本身是个成熟的 OLAP 引擎,其对 SQL 语法有较为全面的实现,也就是说 Spark 中的绝大部分 SQL 算子在 ClickHouse 中都能找到对应的实现,我们不需要投入大量人力重新实现每一个 SQL 算子,而是打通整个执行流程即可。另外从系统架构的角度看,该方案需要的是一个能替换 Spark Task 数据处理流程的 C++ 版本的实现。而 Spark Task 中还包括了和整个 Spark 框架集成的其他逻辑,比如 RDD 反序列化、Shuffle 体系的对接、广播数据的分发、Metric 的搜集等,这些逻辑还是需要保留的。所以我们需要的不是一个 ClickHouse 集群,而是要把 ClickHouse 改造成一个动态链接库,在 Spark 中真正需要进行数据处理的时候,才把执行计划通过 JNI 接口传给 ClickHouse 的 C++ 代码。
接下来讨论一下 ClickHouse 的选型,或者说有没有其他更加适合的 SQL 引擎来支撑这个解决方案呢?实际上当前有不少其他引擎的性能和 ClickHouse 不相上下,不过 ClickHouse 的性能依然处于第一梯队,其作为一个成熟的计算引擎也经过了大量客户的打磨,所以用 ClickHouse 来作为 SQL 内核引擎提升 Spark 性能是非常合适的。

2 ClickHouse 性能优势解析
前面讲到了 ClickHouse 的性能优势,这一部分我们先介绍一些 CPU 性能优化的常见技术手段,然后介绍一下 ClickHouse 在性能优化方面的一些具体表现。
2.1 CPU Pipeline – 向量化的基础
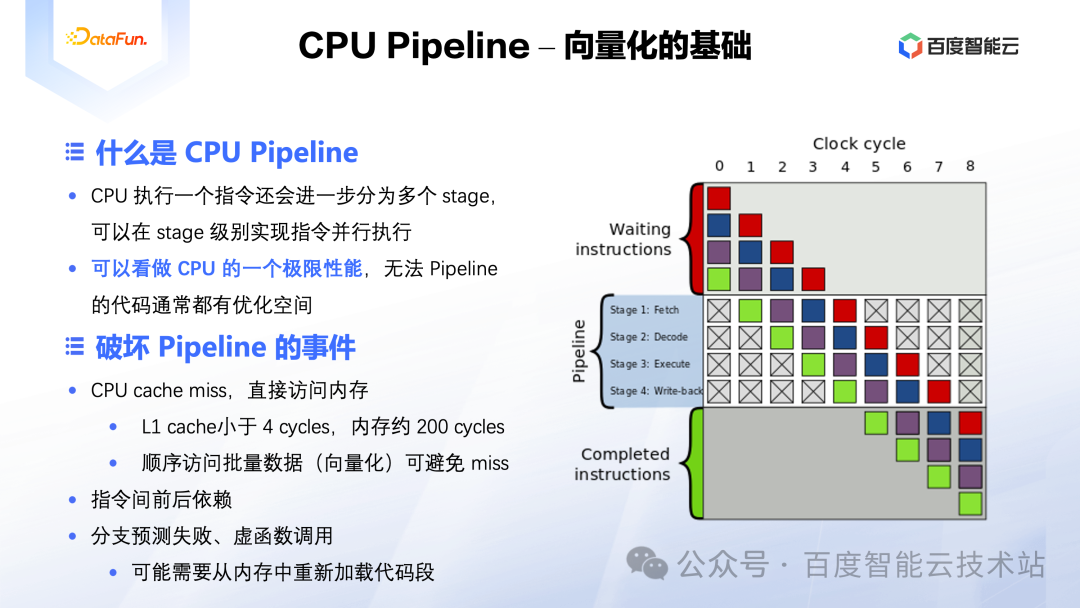
首先要介绍一下 CPU Pipeline 技术,这是现代 CPU 性能优化的一个核心技术,也可以认为是现代向量化技术的一个基础。
如图所示,CPU 在执行一个机器指令时,还要进一步分为多个 Stage,通常每个 Stage 的处理耗时占用一个时钟周期。比如 Intel Xeon 6271C 的主频为 2.6GHz,那么它的一个时钟周期还不到 1 纳秒。以常用的两个数求和的 add 指令为例,它可能要进一步划分为 Fetch、Decode、Execute、Write-back 四个 Stage。如果我们要连续执行两个 add 指令,那上一个执行到 Decode 阶段的时候,Fetch 模块其实是可以执行下一个指令的 Fetch 阶段的,如果所有的指令都能以类似的方式让 CPU 所有模块都跑起来,那就可以认为跑满了 CPU Pipeline,在这个角度也就实现了 CPU 性能的最大化。
通常 CPU Pipeline 无法被打满主要是由于数据访问延迟导致的,比如某个 add 指令要操作的数据不在 CPU Data Cache 中,而是在内存中,那等到该数据的加载完成要消耗大约 200 个时钟周期,这个阶段 CPU 完全处于空闲状态,造成了大量的计算资源浪费。无法 Pipeline 的另一个原因是指令间有前后依赖,比如下一个 add 指令的操作数是上一个 add 指令的计算结果,那下一个指令就必须等上一个完全执行完以后才能开始,这也会造成一定的计算资源浪费。还有一个常见的无法 Pipeline 的原因是分支预测失败、虚函数调用等,这里的原因其实是下一个要执行的指令没有加载到 CPU 的 Instruction Cache 中,而要从内存中加载这些指令同样需要大约 200 个时钟周期[2]。
这里还有一点没有说明的就是,内存上的数据、指令是如何加载到 CPU 的 Data Cache 以及 Instruction Cache 中的呢?我们可以简单认为是 CPU 自动加载的。我们的代码编译后生成的机器码最终是以字节序顺序存放的,CPU 在执行当前指令的时候会自动加载后续的指令到 Instruction Cache 中,这个过程叫做 Prefetch。同样在处理数据的时候,会把当前指令操作的内存地址后续数据加载到 Data Cache 中,这个过程叫做 Preload。这些预加载过程是通过总线把内存中的信息加载到 CPU 中,它的延迟较大,但是带宽同样很大,那么平均下来单个字节的加载耗时就非常小了。如果计算过程全部能命中 CPU Cache,那么 CPU 的 Pipeline 就基本可以跑满了。所以 ClickHouse 这样的引擎才会把数据以列式存放,CPU 处理过程中的预加载就可以准确、及时的把数据预加载到 CPU Cache中。
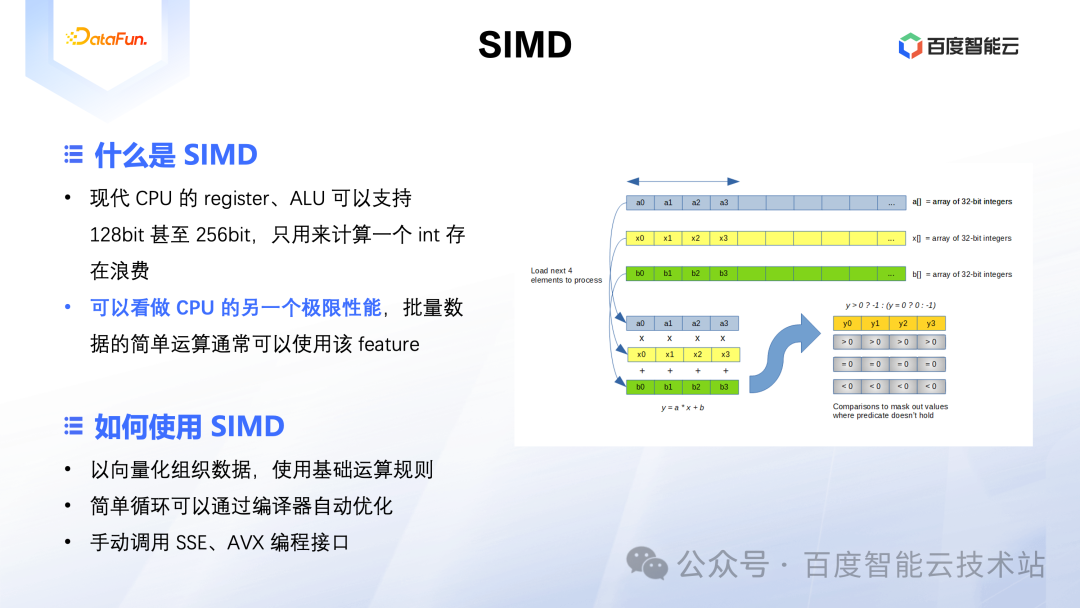
2.2 SIMD 简介
前面讲到的 Pipeline 可以理解为是一种指令级的并行技术,而 SIMD 可以认为是一种数据级并行的技术,它的全称为 Single Instruction Multiple Data。其基本原理为当前 CPU 的寄存器、ALU 等可以支持的位宽通常可达 128 位或者 256 位,如果一次只对两个整数进行求和的话,只占用了 32 位,依然有明显的计算资源浪费。
而如果我们有一大批整数需要求和的话,那就可以四个一组(甚至八个一组)来计算,也就是一个 add 指令完成四组数的计算,那计算效率就会有四倍的性能提升。所以 SIMD 也可以看做是 CPU 的另一个极限性能,尤其在 SQL 引擎领域要做大量数据处理的场景,是有很大的可能用上该优化技术的。
通过上述分析,我们也基本清楚了使用 SIMD 技术的两个基本要求:一个是大量数据进行相同的计算逻辑,另一个是要求计算逻辑必须是 CPU 的基本指令。所以这也是 ClickHouse 选择列式存储的另一个重要原因,我们以如下 SQL 为例:
select f1 + f2, f3, f4, f5, f6 * f7 from tbl
如果每个字段的数据都单独连续存放,那么其计算过程也是按列进行的,也就是先完成「所有」的「f1 + f2」计算,这样就符合了 SIMD 技术的两个基本要求。并且类似这样的简单计算,编译器大概率会自动生成使用SIMD指令的机器码。当然在一些稍微复杂的场景下,也可以调用 SSE、AVX 等编程接口来使用 SIMD 技术。
2.3 ClickHouse 中的 Native 技术
这里我们通过一个例子看下 ClickHouse 中是如何应用类似 Pipeline、SIMD 这样的 Native 技术的。
如图所示的简单聚合 SQL,左边是 Spark 中实际执行的 Java 代码,可以看到比我们前面介绍的一百万个整数求和的代码稍微复杂一些,其性能我们也可以有个大体预期。右边的上图是 ClickHouse 中的 C++ 代码,右边下图是蓝色方框中对应的汇编代码。
C++ 代码中实际上看起来是三个循环,前两个还是嵌套循环。这个写法在编译器里有个术语叫循环展开[3]。第一个 for 循环体的特点是把数据都加到一个 partial_sum 数组里了,这就是循环展开的核心改动,让这个 for 循环里的计算互相没有任何依赖,通过这个改动就可以让这个 for 循环的执行用上 Pipeline 优化了。一般来说编译器会自动做这个优化,但是有些代码无法自动优化,就需要手动写成这个样子。
再看汇编代码里的 xmm0、xmm1、xmm2,这些寄存器就是 SIMD 指令用来临时存放数据的,而 paddq 就是一个 SIMD 指令,它可以做到同时进行一组求和运算。假如这里是对 int 类型求和,int 是 32 位,而 SIMD 指令一次可以算 128 位(这就是为啥上面 unrool_count 初始化要那么写了),所以就是一次性可以算 4 个 int 求和,就这一段代码来说其执行效率就是不用 SIMD 的 4 倍。

2.4 ClickHouse – C++ 模板
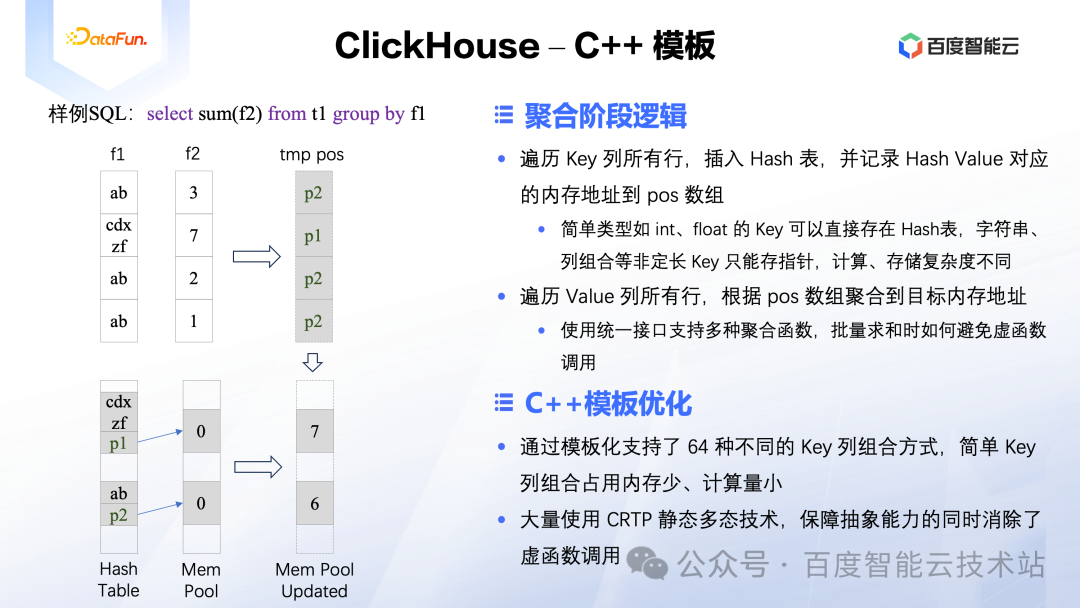
这里再介绍一个 ClickHouse 中较为普遍的优化手段:大量使用 C++ 模板,我们通过一个分组聚合的例子来进行分析。
如图所示的分组聚合 SQL,我们只分析其聚合阶段的执行逻辑,进一步会分为两个阶段。第一个阶段只遍历 Key 列,遍历的同时插入到 Hash 表中,Hash 表的 Value 是个指针,指向的地址用来保存最后的聚合值,另外还会生成一个 tmp pos 数组,记录每一行对应的 Hash 表 Value 值。第二个阶段遍历 Value 列,因为 tmp pos 中记录了每一行对应的聚合结果的位置,遍历的同时就可以完成聚合了。
这里可能遇到的问题是不同类型的 Key 列占用的内存空间大小是不一致的,而大部分的 Key 列宽是固定的,对于字符串作为 Key 列的情况,其宽度还是不固定的。这样的话,对 Hash 表中不同类型的 Key 列处理方式是不同的,而 Hash 表还需要定义一个统一的接口。如果采用传统的面向对象多态、继承的方案来解决该问题,会造成大量虚函数调用,影响执行效率。所以 ClickHouse 这里通过 CRTP 技术在解决接口抽象、多态需求的同时,还保证了性能的最大的化。
3 Spark Native 加速方案设计和实现
通过前面部分的介绍,我们已经对基于 ClickHouse 加速 Spark 的技术背景、可行性有了充分了解,下面我们介绍一下该加速方案的设计和实现。
3.1 整体方案 – 设计原则
我们这里提出了两个设计原则。
首先是保证和原生 Spark 的兼容性。主要的出发点是保证用户可以没有任何负担的使用该加速方案,除了享受到性能优化的优点之外,几乎不需要付出任何额外的代价。我们预期中唯一的额外代价就是一个开关配置,让用户决定是否开启该加速方案。而在兼容性落地方面,首先要保证的就是 SQL 语义的一致性,也就是是否开启 Native 加速方案不会改变 SQL 的执行结果。兼容性另一个要考虑的点是,要沿用 Spark 现有的调度框架。一方面可以控制我们的改造成本,复用 Spark 调度框架;另一方面,开启 Native 加速后的运行时框架、资源调度配置项都保持一致,方便用户对 Spark 保持运维体验的一致性。
其次是追求性能提升比例的最大化,这也是该项目存在的意义。原则上说,ClickHouse 各算子的性能都已经实现了充分的优化,但是我们在推进每一个功能对接的时候,总会遇到一些实现细节的不一致,甚至也会遇到 ClickHouse 未实现的算子,那么我们对 ClickHouse 改造、新增的功能要保持和其他功能一致的性能水平。另外从宏观角度来说,Spark 和 ClickHouse 对内存中数据的表达方式不一致,两者之间互相转换会增加额外的性能开销,所以我们要尽量避免两者之间的数据流动。

3.2 整体方案 – 执行计划
接下来我们看下在执行计划层面的实现方案,这也是整个实现方案的框架性设计。
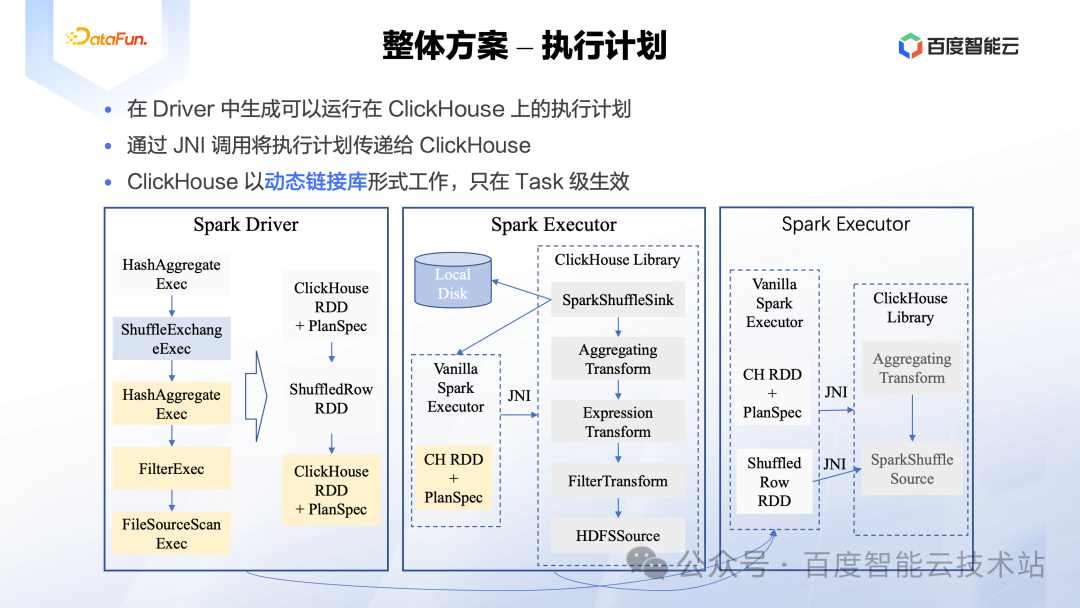
这里依然以一个分组聚合的 SQL 为例介绍执行计划层面的设计。在 Driver 中生成物理计划后,通过调用 doExecute 接口可以生成对应的 RDD。不过在 Native 加速方案中,生成的是可以运行在 ClickHouse Library 上的 RDD,并且每个Stage只有一个 ClickHouseRDD,这个 RDD 将这个 Stage 中的所有 SQL 算子都参数化并记录下来。而在 Executor 中,当该 RDD 真正执行的时候,会通过 JNI 调用将序列化后的 SQL 算子下发给 ClickHouse Library,在 ClickHouse Library 的 C++ 代码中,会根据收到的 SQL 算子参数重新构建出 ClickHouse 的算子, ClickHouse 完成类似的处理工作后会把执行状态通过 JNI 再返回给 Spark。这样 ClickHouse Library 中只完成基于 SQL 算子的数据处理工作,整个计算框架还是一个完整的 Spark。
在下图中间的 Executor 中,我们可以看到有个 SparkShuffleSink 算子,这个算子在 ClickHouse 中原本是没有的,我们需要实现该算子完成数据的 Shuffle 切片逻辑,并生成和 Spark 中一致的数据格式。同理在最右边的 Executor 中,可以看到也有一个自定义的 SparkShuffleSource 算子完成从 Spark Shuffle 服务中读取数据的逻辑。
基于上述讨论,执行计划的整体方案可以总结为如下三个特点:
-
在 Driver 中生成可以运行在 ClickHouse 上的执行计划。
-
通过 JNI 调用将执行计划传递给 ClickHouse。
-
ClickHouse 以动态链接库形式工作,只在 Task 级生效。
3.3 整体方案 – 执行计划序列化举例
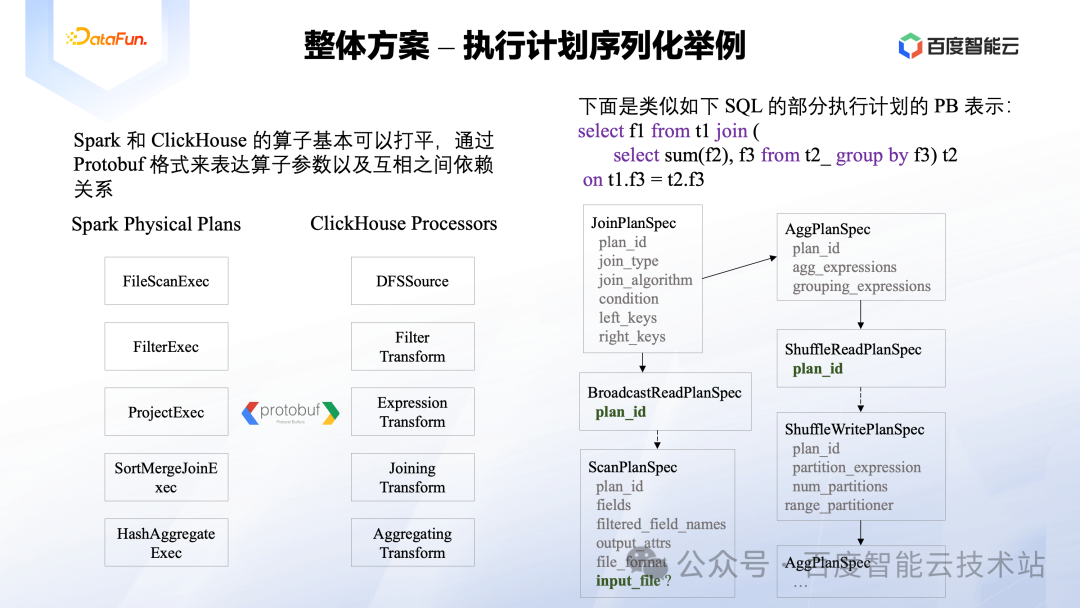
前面讲到了会在 JVM 中将执行计划参数化,并序列化后通过 JNI 下发给 ClickHouse Library,在具体的实现过程中,我们是通过 Protobuf 格式来实现的序列化过程。
如下图左侧所示,绝大部分 Spark 中的 SQL 算子都能在 ClickHouse 中找到对应的 SQL 算子。比如Spark中用来读取数据的算子为 FileScanExec,它可以将 Parquet、ORC、CSV 等任意 Spark 支持的数据类型读取成 Spark 的内存格式 InternalRow。而 ClickHouse 中对应的算子为 DFSSource,Spark 中支持的数据类型,ClickHouse 基本上也都支持,不过该算子最终会输出 ClickHouse 的内存数据格式 Block。
进一步来看,对应算子的构造参数格式虽然不一样,但是参数内容却也是可以对应的上。如下图右侧,展示的是一个 Join SQL 的部分算子序列化为 Protobuf 格式后的示例图,以 Scan 算子为例,无论是 FileScanExec 还是 DFSSource,其参数都可以用 Protobuf 格式的 ScanPlanSpec 进行表达,它们需要的参数无非就是读取的具体文件列表、文件格式、文件结构、过滤字段列表等信息。而这些算子通过前后依赖关系就可以组成一个完整的执行计划。
另外图中可以看到 BroadcastReadPlanSpec 和 ShuffleReadPlanSpec 都只有一个参数 plan_id,这是由于该算子其实是不同 Spark Stage 的一个分割点。比如 BroadcastReadPlanSpec 下面的部分是在一个 Stage 中单独执行的,其执行结果会交给 Spark 的 Broadcast 框架进行广播,最后在执行 Join 的时候发现要依赖广播的数据,那就以这个 plan_id 为参数可以从 Spark 的 Broadcast 框架中找出对应的数据完成计算逻辑。
下图中 ScanPlanSpec 的 input_file 字段也做了加粗,这里也需要做个特别的说明。由于 Protobuf 格式的执行计划来自于 Spark 中的物理计划,而只有物理计划对应的 RDD 在绑定到具体的 Task 的时候,才知道要读取的具体文件信息。所以这里在实现上是需要特殊处理一下的。
3.4 SQL 语义兼容 - 支持 Decimal 类型
前面讲了 Spark Native 加速方案的整体设计,接下来针对一些具体的实现分别做个介绍,以便对该方案可以有个较为全面的了解。首先看下支持 Decimal 类型时遇到的问题。
下图表格中展示了 Decimal 类型的加、减、乘、除四种算术运算的结果类型参数在 Spark 和 ClickHouse 中是不一致的。第二列和第三列展示了在 Spark 中对应结果的精度和标度,第四列和第五列展示了在 ClickHouse 中的精度和标度。其实 Spark 中对精度和标度的推导是进一步参考了 Hive、MS SQL,并且看起来是更加合理的,重点是计算结果不会溢出。而 ClickHouse 大概率只是考虑了实现的简便性,可以看到其精度的推导是个阶梯结果,实际上分别对应了 32 位、64 位、128 位、256 位整数所能表示的最大精度,上图中的代码截图也可以看出如此定义在使用 C++ 模板实现时是比较方便的。
所以这里在我们的 Spark Native 方案中支持 Decimal 类型的时候,就需要对 ClickHouse 中的类型推导逻辑做一个修正,使其计算结果和 Spark 中完全一致,并且还不会导致性能下降。

3.5 调度框架兼容 - Shuffle 对接
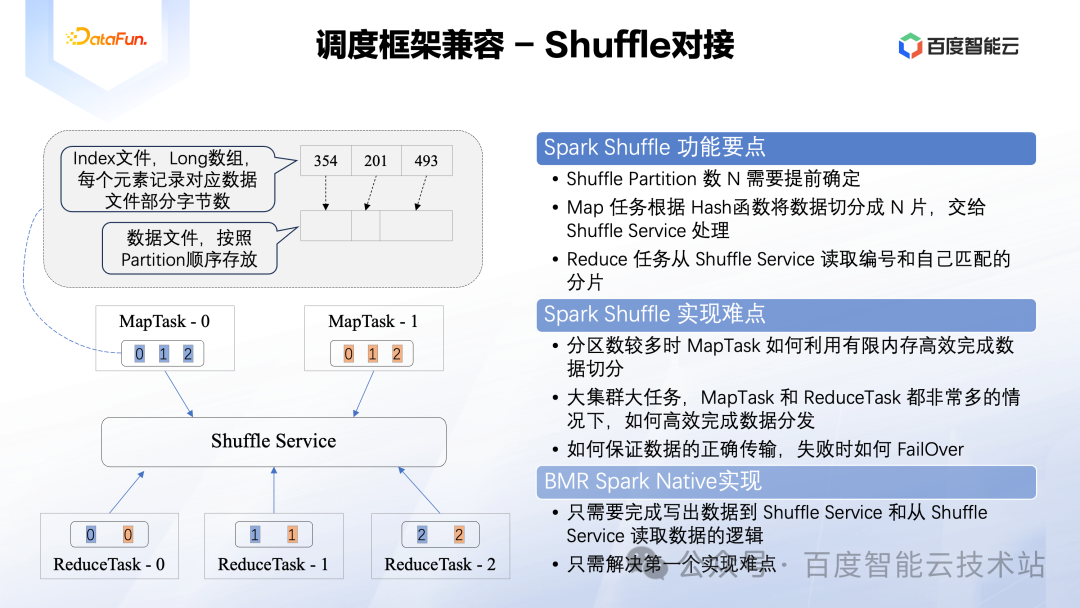
Spark Shuffle 框架是保证其离线任务稳定性的非常重要的一个模块,另外现在社区也有不少其他实现,进一步解决了超大离线任务的稳定性。我们在 Spark Native 实现中的目标也是接入该 Shuffle 框架的同时不影响性能提升的目标。
欲理解 Spark Native 如何完成对 Shuffle 框架的对接,我们需要先搞清楚 Shuffle 框架的运作机制。如下图所示,Shuffle 框架的功能可以简单抽象为接收 MapTask 输出的数据,然后进一步将对应的数据分片下发给 ReduceTask。以上图中两个 MapTask、三个 ReduceTask 为例,MapTask 在完成数据处理后,需要根据数据分区逻辑将数据切分成三份,比如前面的分组聚合 SQL,那 MapTask 的数据分区逻辑其实就是对 Key 列进行 Hash 后对 3 取余。我们将切分后的数据分别编号为 0、1、2,那么编号为 0 的 ResultTask 需要拉取所有编号为 0 的数据分片,这个数据分发逻辑就是通过 Shuffle 框架完成的。
另外关于 MapTask 传给 Shuffle 框架的数据,主要是由两个文件组成的,其中一个 Index 文件记录了每个数据分片的字节数,另一个是存放实际数据的文件,按照顺序记录了实际数据。可以看到这里是不管实际数据的序列化方式的。
Spark Native 加速项目本身对 Spark 的改造不多,但是需要对 Spark 本身的执行机制需要有全面的理解。这里我们就进一步看下 Shuffle 框架实现上的一些难点。首先就是分区数较多并且 MapTask 处理的数据量又很大的时候,如何高效、稳定的完成数据切分。由于 Task 的可用内存是有限的,数据量较大的时候,整个切分过程不可能全部在内存中完成,就要涉及到数据的 Spill,所以这里的性能优化方案较为关键。其次就是大集群、大任务环境,Shuffle 框架如何高效、稳定的完成数据分发,比如集群有 1000 台机器,Map 和 Reduce 任务各有 1 万+的场景下,整个集群的网络、磁盘压力都会非常大。最后就是如何保证数据传输的正确性,以及某些分片的数据丢失后如何 FailOver,Spark 在这些方面已经有了较为完善的解决方案。
回到 Spark Native 的实现角度,我们需要在 ClickHouse 中新增两个算子,一个是 SparkShuffleSink,实现类似 Spark 的逻辑,完成数据的切片逻辑并输出上述的 Index 文件和数据文件。另一个是 SparkShuffleSource,需要完成从 Shuffle 框架读取数据的逻辑。从上述 Shuffle 框架实现难点的角度看,我们的 Spark Native 只需解决第一个难点即可,剩下的事情可以全部复用 Spark 现有解决方案。
3.6 性能优化 - Conditional Join
这里以 Condition Join 为例介绍一下我们在实现过程中的一个性能优化点。
首先我们要介绍一下什么是 Conditional Join,如下图 SQL 所示,这是一个 Join条件中带有不等式的 Semi Join。Semi Join 的语义可以简单总结为只输出左表中符合关联条件的行。它和 Inner Join 的核心区别是,对于关联条件有多行的值都相等的情况下,不会做迪卡尔展开。比如图中的例子,Semi Join 只会输出一行,而如果是 Inner Join 的话,会输出两行,并且内容是重复的。
如上特征的 Join,在实现上是增加了不小的难度。如果只是等值条件,那可以对右表建立一个 Hash 表,遍历左表每一行,在右表中找到匹配行就输出即可。但是由于不等式条件存在,左表的一行在右表中找到匹配行以后,还要对不等式表达式进行求值,满足条件的才可以保留,并且满足条件后就不用继续检测剩余匹配行了,因为不可以重复输出。
这里的关键点就是表达式求值的性能问题,我们都知道,未做优化的表达式求值,会涉及到大量的虚函数调用,这在处理大批量数据时的性能表现会很差。而解决表达式求值性能问题通常是两个手段。一个就是 Spark 中大量使用的 Codegen,通过代码生成消除虚函数调用。另一个就是 ClickHouse 中大量使用的向量化,一次性计算一大批数据,平摊虚函数调用的开销,当然 ClickHouse 中也在向量化的基础上进一步实现了部分算子的 Codegen,可以进一步提升性能。但是目前这两个方案都无法解决上面提到的 Conditional Semi Join 表达式求值性能问题。
还有一种退而求其次的方案,就是先按照 Inner Join 的思路生成一次 Join 结果,然后在其结果上应用向量化的表达式求值,该方案的整体性能预期也不会太理想。这是由于按照 Inner Join 生成 Join 结果其实就会造成大量额外的计算以及生成额外的数据,这本身已经是一种资料浪费了。另外对于上例中的左表第三行数据,用 Inner Join 会输出三行结果,再用 Condition 过滤以后还剩两行,但是 Semi Join 的语义是只保留一行结果,所以还涉及到一个结果去重问题,无形中增加了计算量、复杂度。所以该方案也不够理想。

前面讲到 ClickHouse 现有的向量化、Codegen 都无法解决 Conditional Semi Join 遇到的表达式求值性能问题,这里在解释为什么无法支持之前,需要先简单介绍一下 ClickHouse 中 Codegen(ClickHouse 中称为 JIT[4])的基本原理。
如下图所示,对于一个复杂的表达式,向量化的求值过程就是逐个表达式进行计算。其实单独算一个表达式的过程中还是涉及到了虚函数调用的,不过由于一次可以处理上万行的数据,平摊了虚函数调用的开销。另外一个表达式算完上万行数据以后,还需要一个临时列来保存这上万行的临时结果以备继续算下一步,这里就产生了较大的额外性能开销。所以 ClickHouse 中使用 Codegen 将计算逻辑改造成一次性完成整个表达式的计算,获得了明显的性能收益。
这里进一步解释为什么 ClickHouse 现有技术手段无法解决 Conditional Semi Join 遇到的表达式求值性能问题。这是因为要想使用 ClickHouse 中的表达式求值,需要提前把所有参与计算的列组织成一个 Block 对象,在 Join 的情况下,就要把所有 Join Key 匹配的行先进行迪卡尔展开。如前面例子,左表值为 2 的有两行,右表值为 2 的有三行,就要先迪卡尔展开成一个 6 行的 Block,才能进行向量化表达式求值。这个展开过程本身就会浪费大量的计算资源,最终性能是不合算的。当然如果不想进行迪卡尔展开,那也无法直接使用 ClickHouse 中的 Codegen。
我们在 Spark Native 中,采用了较为彻底的解决方案:基于左右表原始列直接采用基于 Codegen 的表达式求值,该方案不依赖对关联值匹配行进行迪卡尔展开。当然实现过程中也只是扩展了 ClickHouse 中现有的 Codegen 框架,让它支持 Column 下标引用的Input。同时我们在实现该功能的时候,也需要对 ClickHouse的 Join 执行框架做些升级改动,使得其可以支持我们的设计方案。另外我们也发现 ClickHouse 目前的 Codegen 支持的函数也较少,我们对其进行了一些扩展。

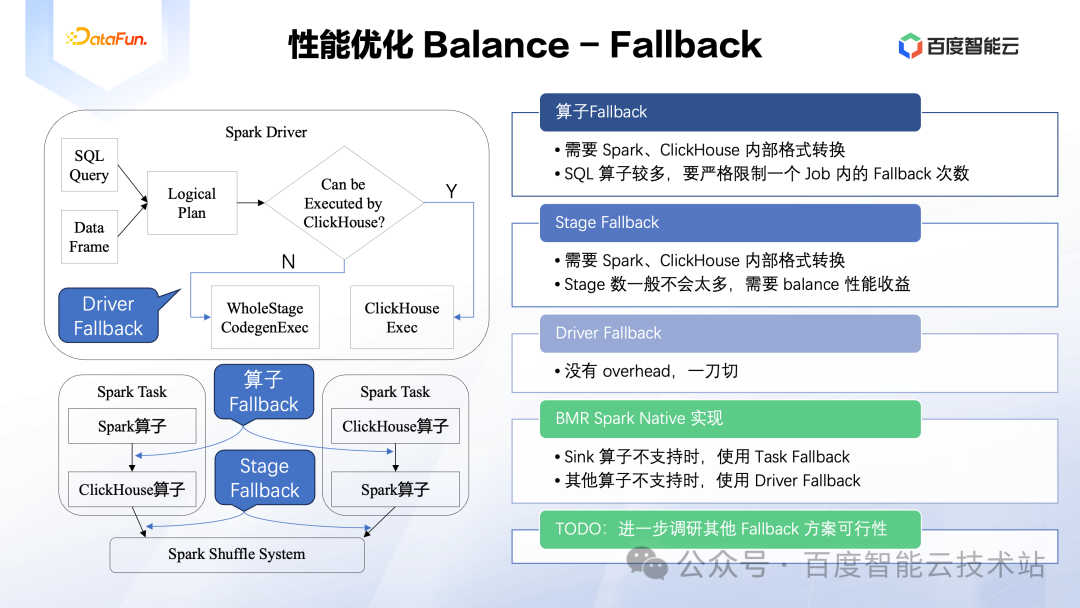
3.7 性能优化 Balance - Fallback
由于 Spark Native 性能优化本身是一个较为复杂、长期的项目,算子、函数的覆盖度是逐步实现的,如果等所有的功能都完全覆盖以后才上线,那是非常不合算的。那么对于用户一个复杂的 SQL,其中可能只有一小部分算子无法被 Spark Native 支持,而其他可以支持的部分却可以获得很大的性能提升,这里理想的解决方案就是只用 ClickHouse 处理其中可以支持的部分,剩下的部分 Fallback 回原生 Spark 中运行。当然也存在先用原生 Spark 执行一部分算子,再 Fallback 到 ClickHouse 的情况。
在实现上,我们可以将 Fallback 分为三个场景。一个是算子 Fallback,比如 Scan 由 Spark 完成,而接下来的 Filter 由 ClickHouse 完成。由于 Spark 和 ClickHouse 中内存数据格式不一致,这里就涉及到数据格式转换,另外也需要通过 JNI 调用来完成此操作,会带来额外的性能开销。所以我们要严格限制算子 Fallback 的应用,不可大量使用。另一个是 Stage Fallback,顾名思义就是上一个 Stage 可能是跑在 Spark 中,而下一个跑在 ClickHouse 中,这里也需要进行数据格式的转换,不然下一个 Stage 从 Shuffle 读取的数据是无法解析的。最后一个是 Driver Fallback,这里的逻辑比较简单粗暴,就是 Driver 中发现 SQL 无法用 ClickHouse 执行的情况下,直接 Fallback 到原生 Spark。它的特点是几乎没有额外的性能开销,起码能做到原生 Spark 的性能不会回退。
当然我们设计 Fallback 机制的原则也是要起码保证原生 Spark 的性能不会回退,所以通常会采用较为保守的策略。目前 BMR Spark Native 中采主要采用了两个 Fallback 策略。一个是对于仅有 Sink 算子不支持的场景,采用 Task Fallback。这是由于 Spark 支持的数据格式较多并且 Sink 的逻辑较为复杂,在 ClickHouse 中保证语义完全一致性的开发成本较高,而仅 Fallback 这一个算子也依然可以获得明显的性能提升。另一个策略就是 Driver Fallback 了,这样用户可以透明使用 Spark Native。
4 加速效果分析
通过前面部分的介绍,大家对 BMR Spark Native 应该有了一个初步的了解,这里进一步看下其性能表现。
4.1 TPCDS 性能
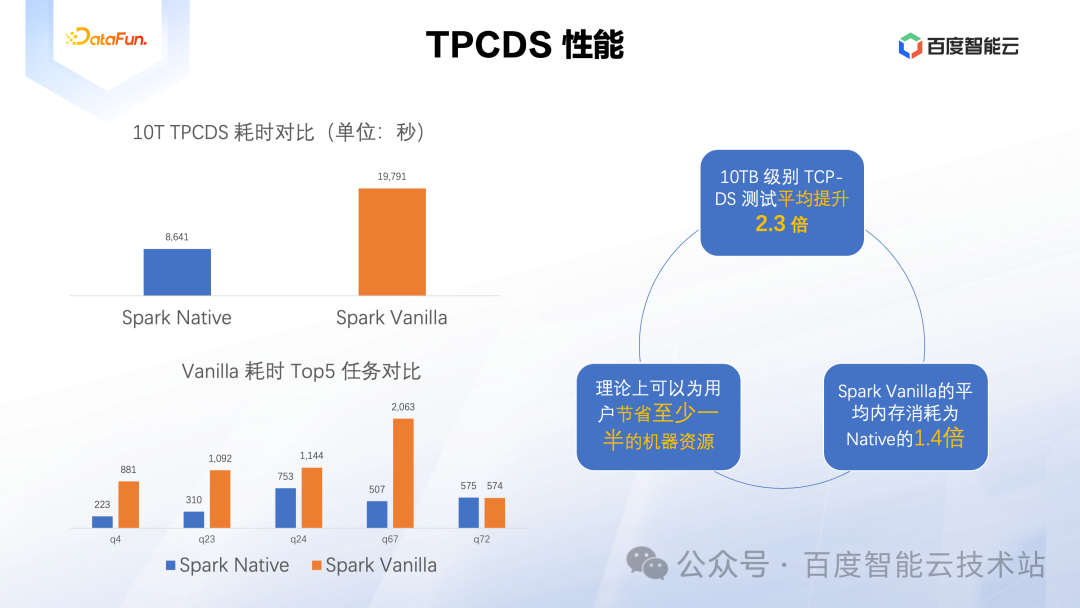
我们使用 10T 规模的 TPCDS 进行了性能测试,整体上有 2.3 倍的性能提升。
这里 2.3 倍性能提升的意思是,对于所有 TPCDS SQL 的执行耗时总和,Spark Vanilla(原生 Spark)总耗时是 Spark Native 的 2.3 倍。其在应用场景的意义是,对于一个 10 台机器的空闲集群,用 Spark Vanilla 运行一个任务需要 1 小时跑完,那么用 Spark Native 运行同样的任务只需不到半小时,或者说把集群规模减少到 5 台,那么用 Spark Native 运行同样的任务也在 1 小时内能跑完。所以其现实意义就是可以节省至少一半的机器成本。另外我们在测试中发现 Spark Native 消耗的内存更少,这同样可以贡献到成本节省比例中。
另外我们选取了 Spark Vanilla 耗时最多的 5 个 SQL,可以发现其中有三个的提升比例超过了 3 倍,而 Q72 没有任何性能提升。下面我们针对其中的典型场景做进一步的分析。
4.2 TPCDS Q23 耗时分析
前面我们看到 Q23 有 3.5 倍的性能提升,我们通过对该 SQL 的特性进行简单的分析来看下 Spark Native 的性能表现。
Q23 的 SQL 源码[5]参见 GitHub,其执行过程会分为多个 Stage,这里挑选其中耗时较大的五个 Stage 进行分析。我们发现 Spark Native 在如下三点上性能表现较好。一个是扫描、过滤、Shuffle Write 等「简单」算子,他们都比较适合使用向量化、SIMD 技术来进行优化。另一个是 Hash 相关 Join、聚合算子有较为明显的性能提升,这是由于 ClickHouse 在相关场景有较多性能优化。第三个是 ClickHouse 基于列式组织的 Shuffle Write 数据,可能会有较高的压缩比,导致 Shuffle 数据较少。不过目前看来该优化还不具备普适性,不过还没有发现 Shuffle 数据量膨胀的情况,所以起码不会带来性能退化。

4.3 TPCDS Q72 性能分析
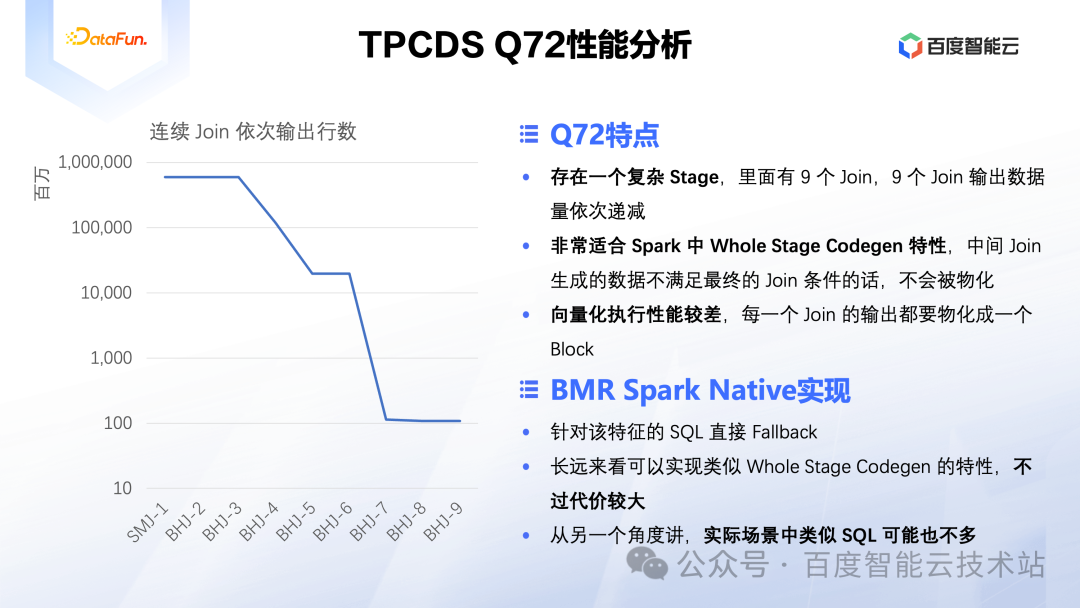
前面提到了 Q72 的性能没有任何优化,实际上在 BMR Spark Native 的实现中,发现该类型的 SQL 其实暂时不太适合用 Spark Native 加速,我们直接在 Driver 中将其 Fallback 了。下面通过分析 Q72 的 SQL 特征,看下为什么 Spark Native 无法加速该 SQL。
我们查看 Q72 的 SQL 代码可以发现,里面有大量的 Join,分析执行日志可以看到,存在一个较为复杂的 Stage,仅该 Stage 里就有 9 个 Join,另外这 9 个 Join 输出的数据呈依次递减的趋势。如下图所示,展示的是整个 Stage 中每个 Join 依次输出的数据量,从最开始的将近一万亿行,减少到最后的一亿多行,整体数据量都比较大,不过依然减少了一万倍。
这样的 SQL 实际上是非常适合 Spark 中的 Whole Stage Codegen 优化的,因为优化后整个 Stage 的处理逻辑是作为一个整体来处理数据的。当处理左表的某一行数据的时候,会依次执行所有的 Join 逻辑,当某一个 Join 中无法匹配的时候,这一行数据就直接丢弃了,只有那些满足所有 Join 条件的行才会最终输出。而在 ClickHouse 中执行这么多连续的 Join 的时候,每执行完一次 Join,就要产生一次中间结果,而实际上只有万分之一的中间结果最终是有效的,其他的中间结果都被丢弃了,那么生成这些中间结果的过程也就浪费了大量的计算资源。
基于这样的特点,我们在 BMR Spark Native 的实现中直接将该类型的 SQL 采取了 Driver Fallback 的策略。从长远来看,有两个方案。一是在 ClickHouse 中实现类似 Spark 中的 Whole Stage Codegen 的优化机制,不过这个实现的代价较大,需要大量人力投入。而从另一个角度看,在我们和大数据业务团队长期的对接过程中,也很少会见到这么多连续 Join 的 SQL。所以是否要做进一步的优化还需要根据实际业务推进情况,再做进一步的考虑。
4.4 欢迎大家试用体验
最后欢迎大家在百度智能云 BMR 中试用 Spark Native 优化功能。
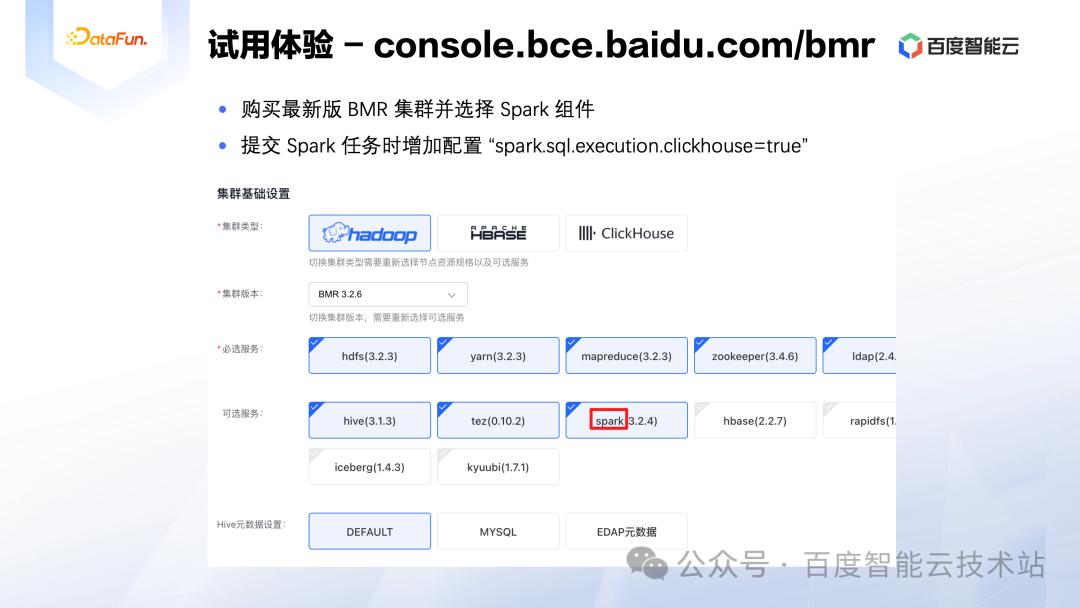
如下图所述,在百度智能云中打开 BMR 产品,或者直接访问:console.bce.baidu.com/bmr,购买最新版 BMR 集群并选择 Spark 组件,即可完成集群的创建。在提交 Spark 任务的时候,只需要增加一个配置「spark.sql.execution.clickhouse=true」即可体验该功能。另外目前只支持 Parquet 和 ORC 格式的数据源,我们推荐优先使用 Parquet 格式。
参考链接
-
示例代码:https://github.com/copperybean/study-codes/blob/main/java/sum-ints.java
-
David R. O’Hallaron Randal E. Bryant. Computer Systems: A Programmer’s Perspective, 3 Edition. Figure 6.23
-
循环展开:https://en.wikipedia.org/wiki/Loop_unrolling
-
JIT 介绍:https://clickhouse.com/blog/clickhouse-just-in-time-compiler-jit
-
Q23 SQL 源码:https://github.com/databricks/spark-sql-perf/blob/master/src/main/resources/tpcds_2_4/q23b.sql
—————— END ——————
推荐阅读
百度&YY设计稿转代码的探索与实践
如何实现埋点日志精准监控
从打点平台谈打点治理
手把手教你用Spring Boot搭建AI原生应用
Baidu Comate帮开发者“代码搬砖”,2天搞定原先3周工作量







![Linux[高级管理]——Squid代理服务器的部署和应用(传统模式详解)](https://img-blog.csdnimg.cn/direct/be4467ce207541fdb175c897344aeb68.png)